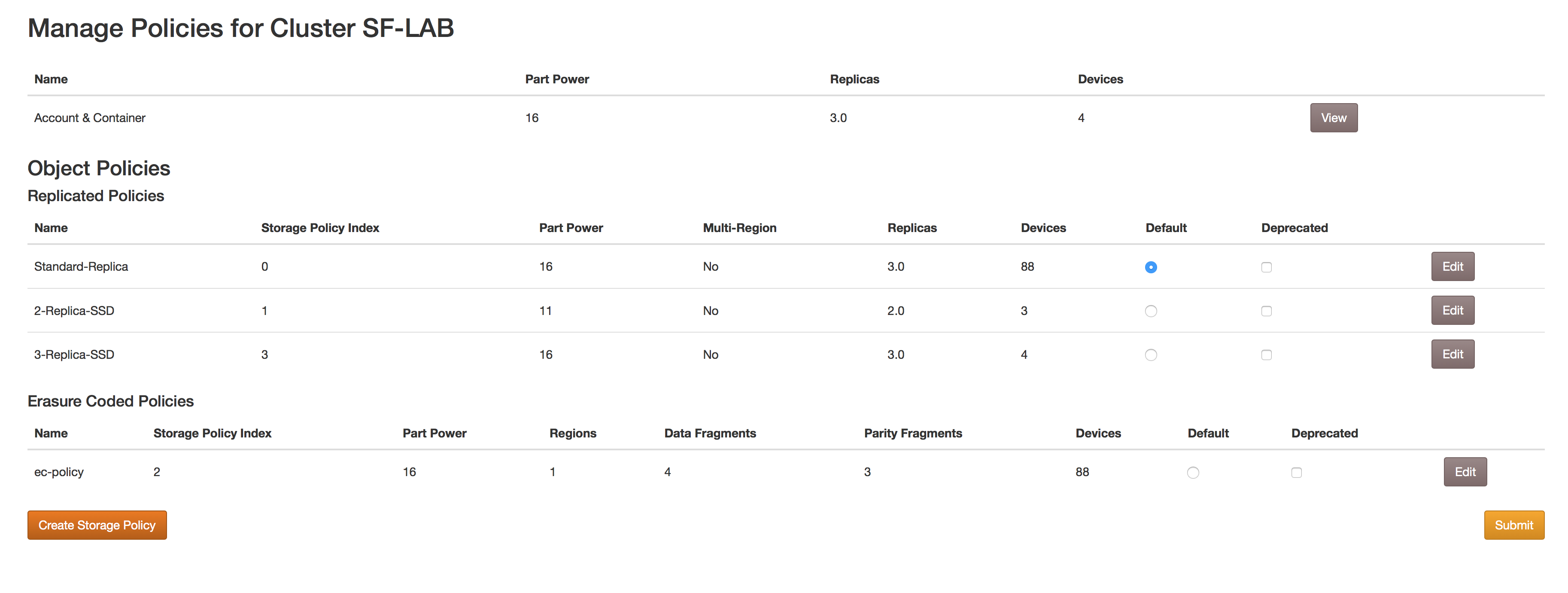
Cluster Storage Policies, Datacenter Regions & Zones¶
SwiftStack Storage Policies¶
Storage Policies Overview¶
Before placing object data into SwiftStack, users create a container which holds the listing of all objects stored under the container's namespace. Objects placed into the container's namespace will be stored according to the object data storage policy assigned to that container.
Each storage policy will have its own ring, and each ring will define which drives can be used to place objects stored in the Storage Policy.
Client specifies storage policy on container / bucket¶
Swift or AWS S3 clients may select the Storage Policy when they create the container / bucket. See: Using Storage Policies
All data stored under a container/bucket namespace will be placed according the configuration of the storage policy which was set when the container was created.
Administrator specifies storage policy for File Access¶
For SwiftStack File Access, the administrator creating a filesystem volume will determine the storage policy used for that volume. See: Backing Policies
Storage policy configuration parameters¶
Storage policies allow data to be stored based on the following criteria:
- Data durability strategy – Number of replicas / Erasure code configuration
- Performance of drives
- Data center locations (regions / zones)
- Region read / write affinity
- Efficient data placement based on projected ring size
For a video demonstration of Storage Policies and how to use them in the SwiftStack controller, see: https://www.youtube.com/embed/AFMMrBnTG4M
Storage Polices and SwiftStack 1space¶
Storage policies may also be used in conjunction with SwiftStack 1space. SwiftStack 1space enables creating a single namespace between private SwiftStack Clusters and public clouds (AWS, GCP, etc.). Specific policies may be configured to lifecycle or mirror data between SwiftStack Clusters clusters.
See: 1space Multi-Cloud
Example Storage Policies¶
| Regions | Storage Policy | Overhead |
| 1 | 3 Replicas | 3 X |
| 2+ | 3 Replicas | 3 X |
| 2+ | 2 Replicas per Region | 4 X |
| 1 | 4 Data + 3 Parity | 1.75 X |
| 2+ | 4 Data + 2 Parity per Region | 3 X |
| 1 | 8 Data + 4 Parity | 1.5 X |
| 2+ | 8 Data + 3 Parity per Region | 2.75 X |
| 1 | 15 Data + 4 Parity | 1.27 X |
| 2+ | 15 Data + 3 Parity | 2.4 X |
Example Storage Policy Use Cases¶
The storage policy configuration options of SwiftStack allow a great deal of flexibility in how object data is stored in the cluster. Different options work better for different use-cases. When using storage policies, a single SwiftStack cluster can offer multiple object data storage options at the same time to best serve multiple targeted use cases.
Highly Scalable Flat Storage (Standard-Replica)¶
Client Use Case
Large variety of files and access patterns. Availability and simplicity is most important.
Recommended Configuration
| Policy Type | Replication |
| Number of Replicas | 3 |
| Drive Distribution | All available capacity |
Erasure Coding¶
Client Use Case
Disk space for storage is at a premium. Higher read latency on small (<4MB) files are considered a reasonable trade-off.
Recommended Configuration
| Policy Type | Erasure Coding |
| Fragment Scheme | Appropriate data / parity combination |
| Drives Distribution | Only within the same region |
Highly Available Multi-Region¶
Client Use Case
Data is created and accessed in multiple data center regions, a failure at one site should not disrupt access to storage in another. Each site is fully durable, but will leverage remote site for necessary fragments when necessary.
Recommended Configuration
| Policy Type | Erasure Coding with Multi-Region |
| Fragment Scheme | Appropriate data / party combination for multi-region |
| Drives Distribution | Across multiple regions |
Region Local Storage¶
Client Use Case
Data is only created and accessed from a single site. Access to data from another region should be rare with an expectation of higher latency or reduced availability due to network interruption.
Recommended Configuration
| Policy Type | Single-region Replicas or Erasure Coding |
| Protection Scheme | 3 replicas or appropriate data / parity |
| Drives Distribution | Only within the same region |
Storage Policy Configuration Notes¶
Once a policy has been pushed to the cluster: * It cannot be deleted, only deprecated. * Its settings cannot be changed with the exception of changing:
- the default status
- the deprecated status
- the read or write affinity settings (see Storage Policies Configuration Options)
Only one policy can be default.
Once a container has been created with a policy, its policy may not be changed.
Default Policy¶
The "Standard-Replica" policy, or whatever other policy has been marked as Default will be the storage policy applied to any container which has not had x-storage-policy set. Any object policy can be designated the default. If you edit the Default Policy on the Storage Policy List page, click the Submit button to save changes.
Deprecated Policies¶
Deleting a policy could leave data orphaned on the cluster, so it is not permitted. If continued use of a policy is no longer desired, mark the policy as Deprecated. Existing containers using these policies will still be accessible, but it will not be possible to create new containers using this storage policy. If you edit a policy's Deprecated status on the Storage Policy List page, click the Submit button to save changes.
The "Account & Container" policy¶
This policy is used to define on which drives the account and container database will live. Since Account and Container data is relatively light-weight, yet accessed frequently, this policy should be applied to smaller, faster drives.
Creating Storage Policies¶
On the cluster's Policies tab, click the Create Storage Policy button.
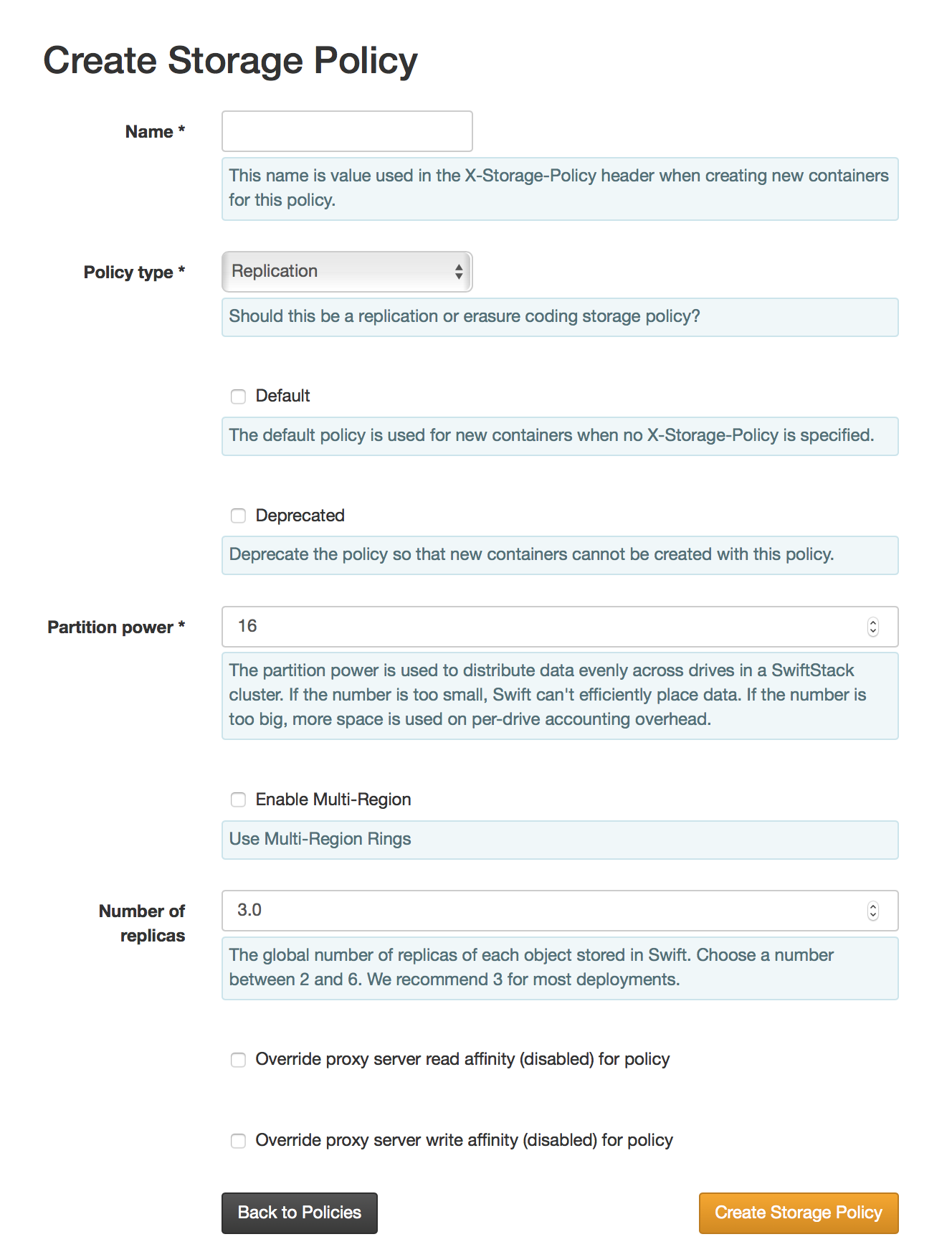
Policy names must follow the following rules:
- Unique
- Case-insensitive
- Contains letters, digits, and/or dash
Mark the policy Default or Deprecated as desired.
Specify the Part Power (10-22). This number is used to determine how much data to move at one time while rebalancing the ring. Use smaller numbers for smaller rings and larger numbers for larger rings.
Choose the Policy Type, Replication or Erasure Coding.
Click the Create Storage Policy button to save.
You can now add drives to your new policy. See Add Policies to the drive(s) for more information.
Replication Policies¶
Specify the number of replicas (2-6).
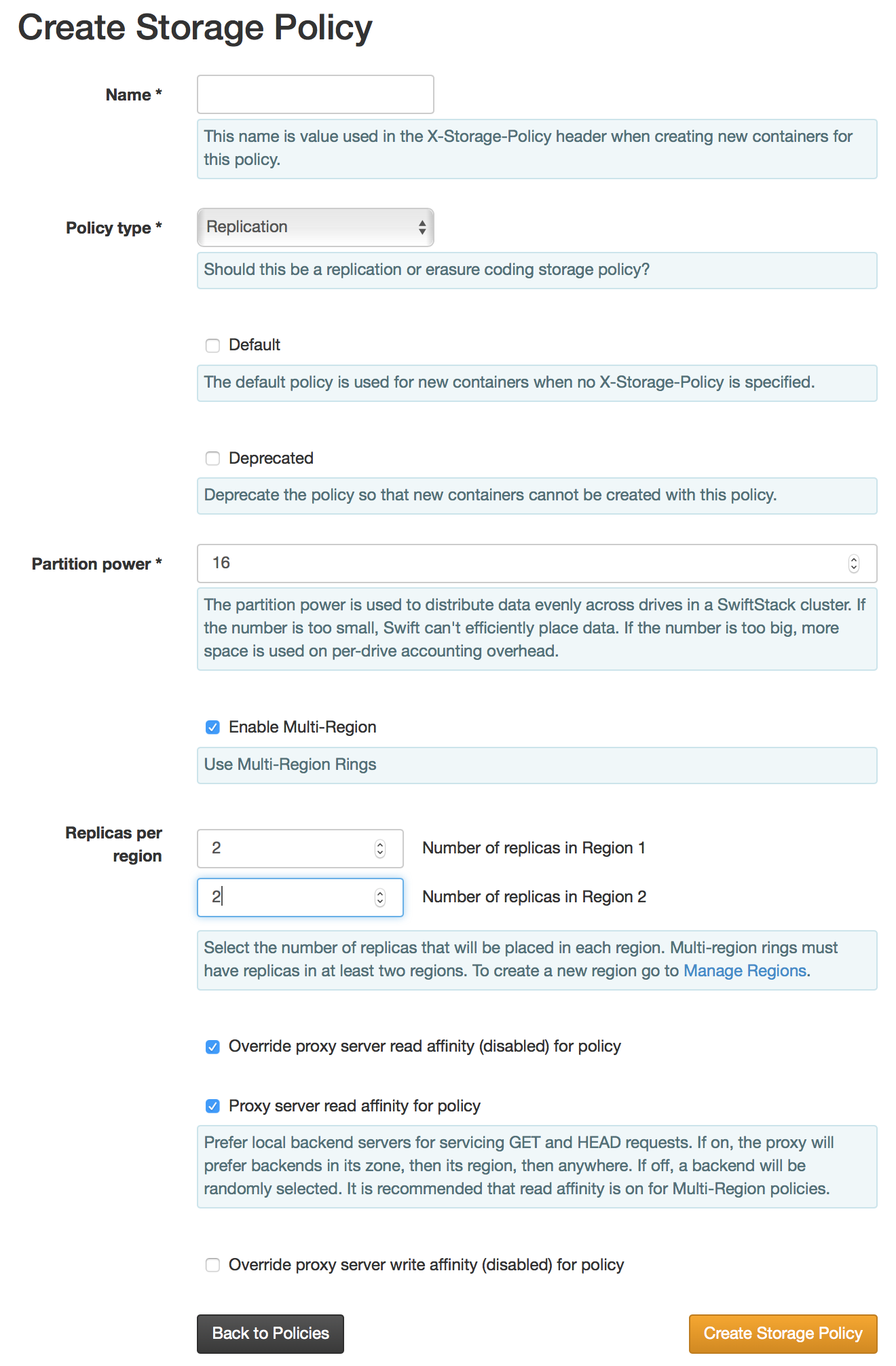
Multi-Region Replica Policies: Default/Algorithmic¶
If it is desired to place data across multiple data center regions, create a storage policy with the desired number of total replicas to be distributed across all data center regions. Use this storage policy when assigning storage devices for all desired regions for this policy.
This is useful to optimize capacity utilization if specific region data placement is not required.
Multi-Region Replica Policies: Deterministic Placement¶
To specify the number of replicas desired in each region, select Enable Multi-Region checkbox. This will then enable the selection of how many replicas are desired in each region for this policy.
Erasure Coded Policies¶
Select the desired Erasure coding fragment scheme. A box in the top right corner will calculate space savings compared to the Standard-Replica policy.
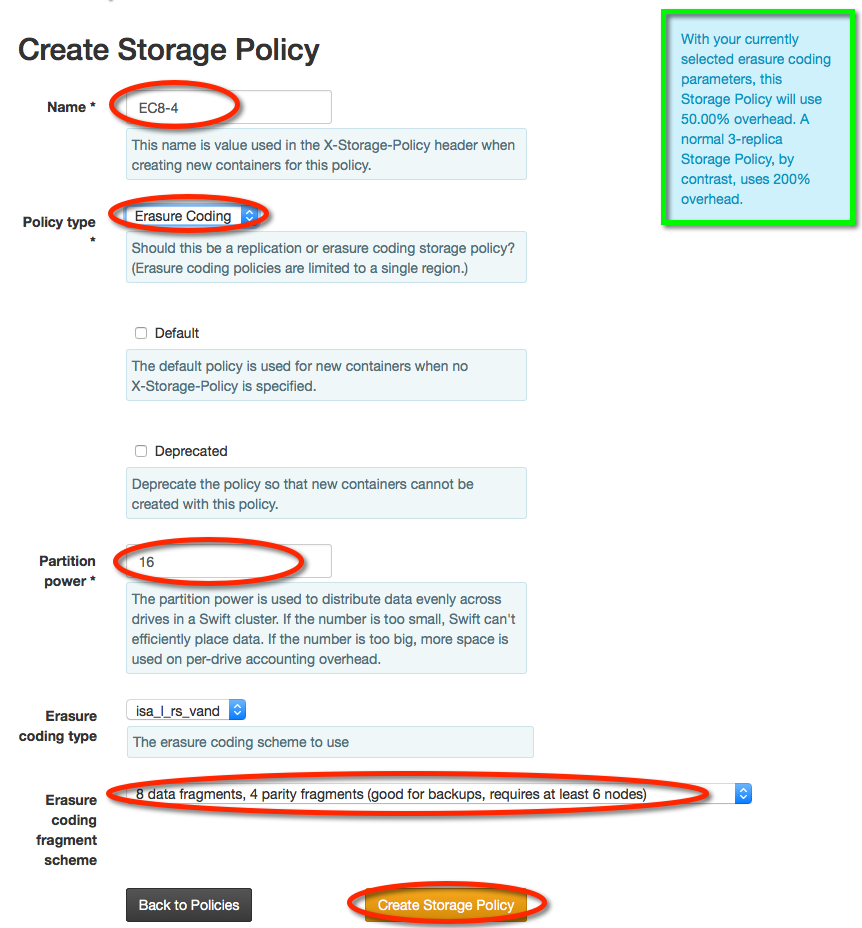
Multi-Region Erasure Coded Policies¶
To specify which regions you want to use for your Erasure Coded Policy, select Enable Multi-Region checkbox.
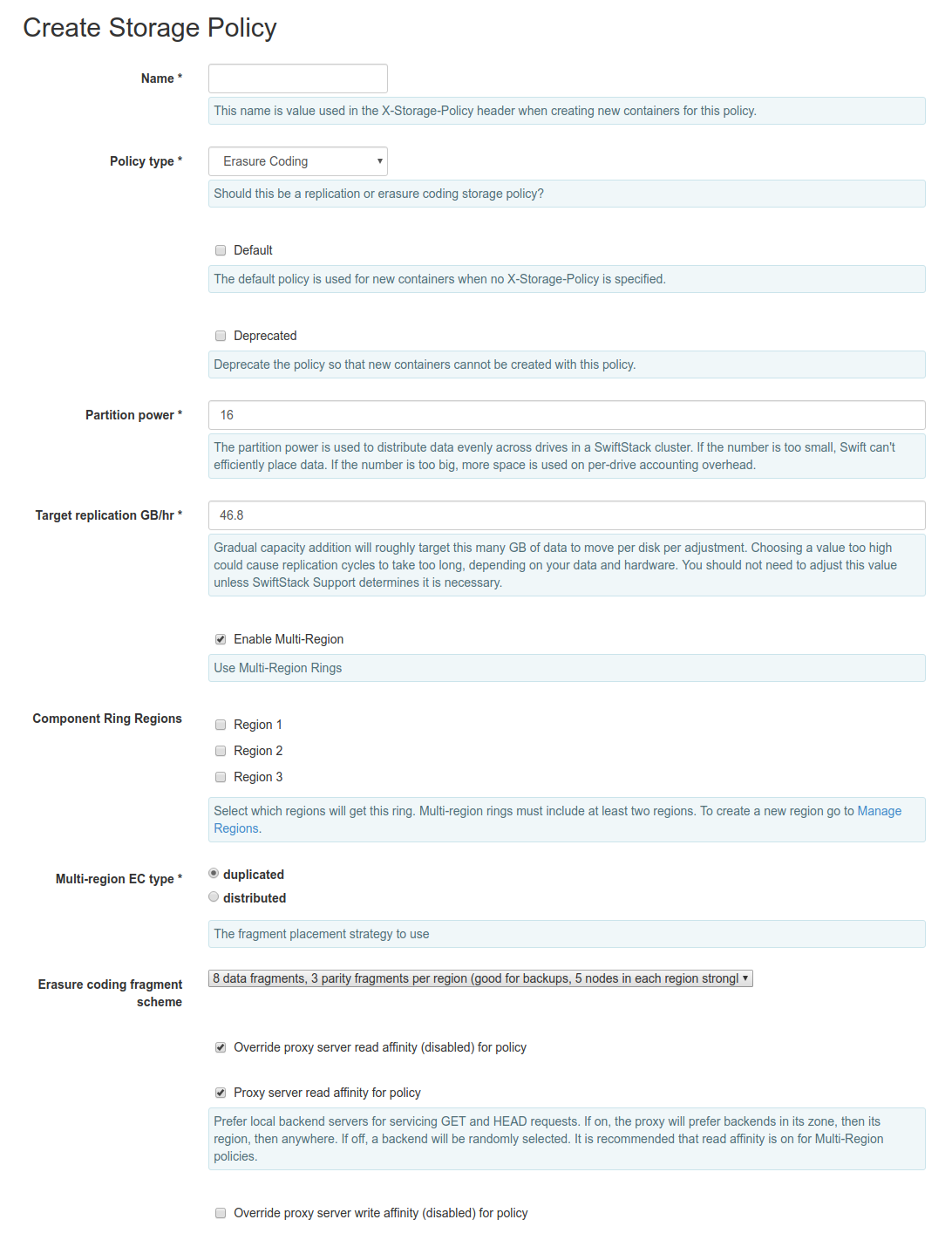
The Multi-region EC type allows you to select to have the policies fragments duplicated between regions or distributed around all regions. Duplicated multi-region schemas have the most robust availability and can more efficiently recover from WAN outages. Distributed polices require more WAN requests on reads and may only be able to maintain availability when a maximum of one remote site is disconnected, but require less backing storage.
Storage Policies Configuration Options¶
Per-policy read & write region affinity¶
There is a cluster-wide setting for storage region read and write affinity. For more information on read and write affinity see Region Affinity.
However, it is possible to configure a SwiftStack cluster with read and write affinity settings for individual storage policies. This can be done using the Edit button on the cluster's Policies tab.

The cluster server read affinity and write affinity settings may be individually overridden per storage policy.

Using Storage Policies¶
The Storage Policies configured for a cluster are enumerated in the info document returned from the swift cluster:
$ curl http://swift.example.com/info | python -m json.tool
{
.. omitted ..
"swift": {
.. omitted ..
"policies": [
{
"default": true,
"name": "Standard-Replica"
},
{
"name": "Reduced-Redundancy"
}
],
"version": "2.2.0.1"
},
.. omitted ..
}
Or using the swift command line client:
$ swift info | grep policies
policies: [{u'default': True, u'name': u'Standard-Replica'}, {u'name': u'Reduced-Redundancy'}]
To create a container with a Storage Policy - send the X-Storage-Policy
header and specify the name:
$ curl -H "X-Auth-Token: <X-AUTH-TOKEN>" -H "X-Storage-Policy: Reduced-Redundancy" \
https://swift.example.com/v1/AUTH_test/mycontainer -
Or using the swift command line client:
$ swift post mycontainer -H 'X-Storage-Policy: Reduced-Redundancy'
To upload or download an object to the container - no change is necessary in the client request. Storage policies are transparent at the object level to all client features (e.g. Large Objects, TempURL, etc)
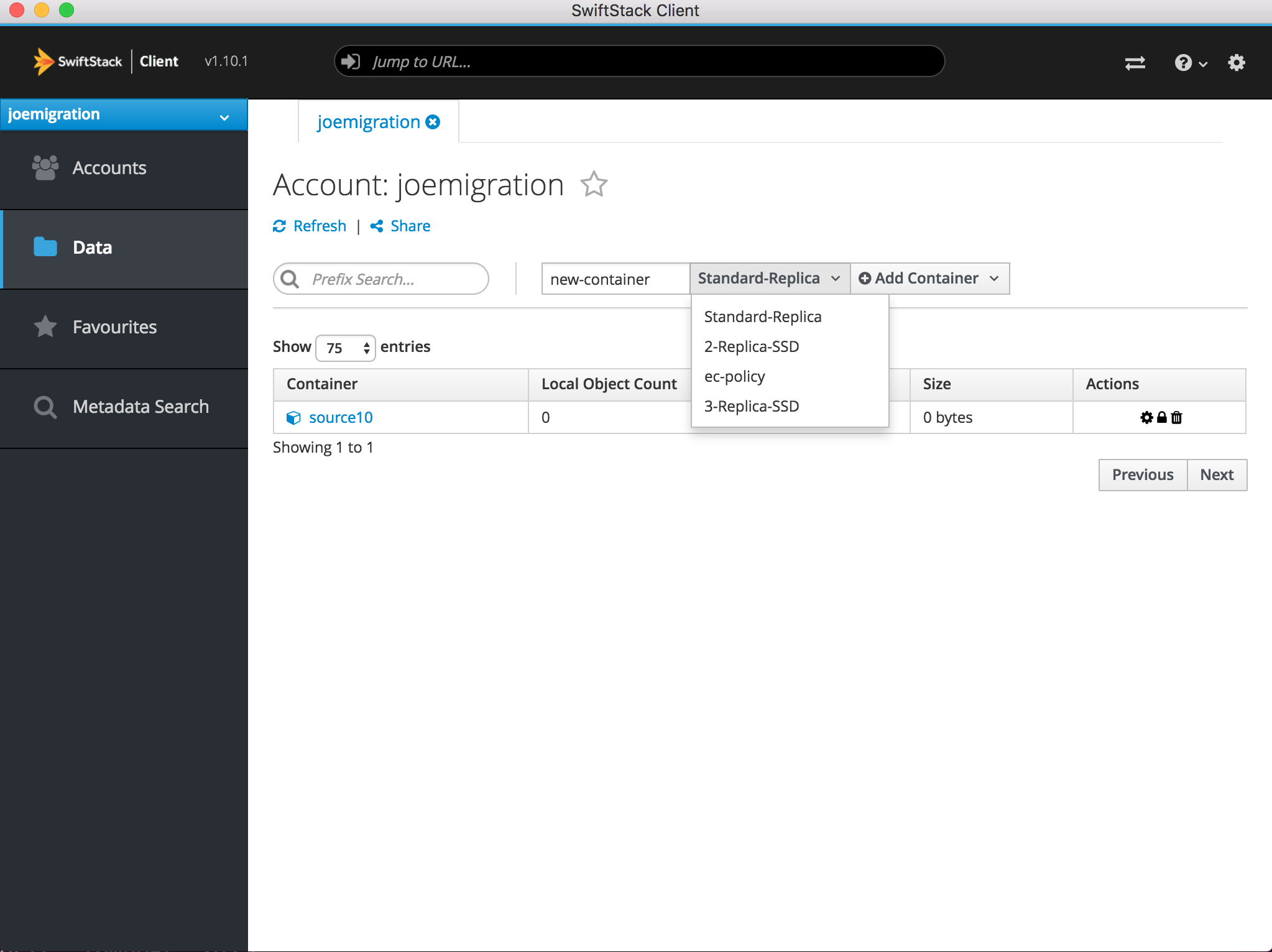
Or using the SwiftStack Client, select a storage policy when creating a container:
Regions and Zones¶
Regions and Zones Overview¶
Regions and zones are defined failure domains within your SwiftStack cluster.
Zones are intended to be used as points of failure zones. For example, if you have a rack and all the nodes in that rack all rely on the same top-of-rack switch, that could be treated as a zone, while a second cabinet, with its own top-of-rack switch, could be another zone. Similarly, if your installation is relying on UPSes, a zone schema could be applied based on nodes connected to a certain UPS or set of UPSes.
Regions have a special designation that may be used by read/write affinity rules, data replication rules to limit WAN bandwidth and enable various storage policies such as deterministic replica placement across regions and multi-region erasure code policies.
While operators define their Zones and Regions, the data placement algorithm used by a SwiftStack cluster will distribute data "as-uniquely-as-possible" across individual drives, storage nodes, data center zones and data center regions.
Multi-Region Cluster Use Cases¶
Multi-region clusters may be desired for a number of reasons:
Offsite Disaster Recovery (DR)
In the event of a natural disaster at the primary data center, at least one replica of all objects has also been stored at an off-site data center.
Active-Active / Multi-site Sharing
Data stored to a data center on one side of the country is replicated to a data center on the other side of the country in order to provide faster access to clients in both locations.
Regional Connectivity Requirements¶
All of the nodes within the cluster must be able to see all of the other nodes within the cluster, even across regions. Typically one of two methods is used to ensure this is possible:
- Private Connectivity - site-to-site via MPLS or a private Ethernet circuit
- VPN Connectivity - a standalone VPN controller through an Internet connection.
Both methods require that the routing information, via static routes or a learned routing protocol, be configured on the storage and proxy nodes to support data transfer between regions.
Bandwidth Sizing¶
Customers will need to specify bandwidth utilized across the private circuit. The size of bandwidth needed will depend on a number of factors:
- Amount of cross-region replication that will be taking place; too small of a circuit will result in bottlenecks for replication traffic.
- Expected number of operations per second. Depending on the setup, proxies generally need to successfully write one or more copies of the object across the region before returning a success. Because the connection is already high latency, these writes will take longer than if contained in a single region. Bandwidth must be sized to support the expected number of operations per second otherwise increased latency may be experienced by an end user of the system.
- Cost. A private circuit will increase in cost based on the distance between regions.
Configure Cluster Regions¶
Region and Zone configuration is available on the Regions tab of the Manage Cluster page.

Default Region¶
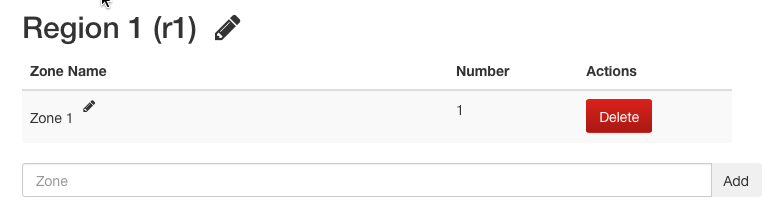
SwiftStack automatically creates a Default Region with one zone for each cluster. If your cluster only has one region, nothing needs to be changed on this page.
Edit Region¶
A region's name may be edited by clicking on the pencil icon next to the name, modifying the name, and pressing enter.

Add Zone¶
Add Zones to each region to define single points of failure like power and network distribution facilities. Zones often have a 1:1 relationship with racks or data center rooms.

Edit Zone¶
A zone's name my be edited by clicking on the pencil icon next to the name, modifying the name, and pressing enter.
Region Affinity¶
When using multiple regions with SwiftStack, both write-affinity (store objects to local nodes first) and read-affinity (read objects preferentially from local nodes) are available.
Write Affinity¶
When handling a data PUT (write) request, a proxy server will normally attempt to write the object data to all of the object's primary storage locations, as described in Swift Overview—Data Placement. In a multi-region cluster this will require some object data being written to another geographic region, potentially causing extra latency before the PUT request completes.
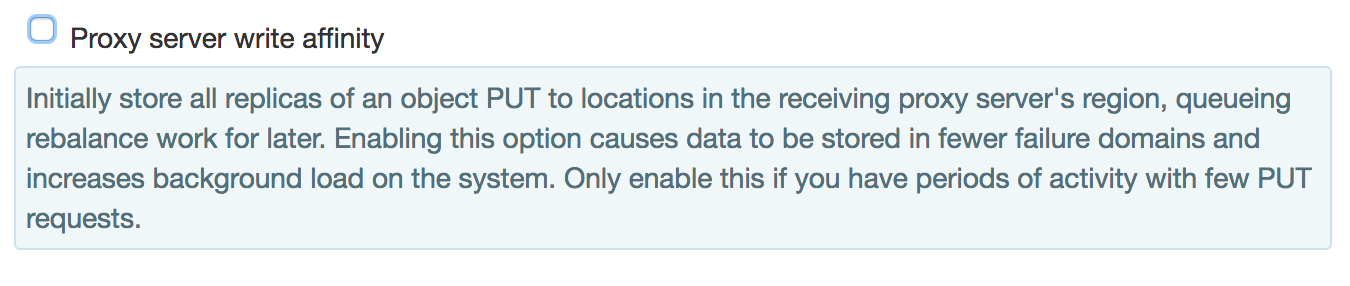
The write affinity setting causes the proxy to initially write object data only to locations in its local region. Data that would normally be written to a remote region is instead written to a temporary location in the local region, which can speed up the completion of PUT (write) requests. This object data is then asynchronously moved to its final location in a remote region background processes.
Before enabling write affinity give careful consideration to the following consequences:
- With write affinity enabled, data is temporarily stored in fewer failure domains.
- The write affinity setting results in increased workload for background processes. It is recommended that write affinity is only enabled when there will be periods of time with few PUT requests, so that asynchronous background processes are able to keep up with the movement of object data to remote regions.
The write affinity setting can be set on the cluster's Tune page under Cluster Settings:
This setting may also be changed for individual policies, see Storage Policies Configuration Options.
Read Affinity¶
When GET (read) requests come into a proxy server, it attempts to connect to a random storage node where the data resides. When configuring a multi-region SwiftStack cluster, some of that data will live in another geographic region, with a higher latency link between the proxy server and the storage node.
SwiftStack allows for you to set read affinity for your proxy servers. When enabled, the proxy server will attempt to connect to nodes located within the same region as itself for data reads. If the data is not found locally, the proxy server will continue to the remote region.
From the cluster's Tune page, you can enable read affinity for your proxy servers to prefer reading data out of the local region first before trying remote regions.

This setting may also be changed for individual policies, see Storage Policies Configuration Options.