OpenStack Swift Architecture¶
Data Storage is Changing¶
The most commonly used storage systems in the enterprise data center today are filesystem storage and block level storage. Filesystem storage is typically deployed as Network Attached Storage (NAS) systems and used for storing and sharing files over a network. Block storage is typically deployed as Storage Area Network (SAN) systems and appears to an operating system like locally attached drives, which is required for running things like databases. Generally organizations have to build a dedicated pool of these storage systems for each application (e.g., CRM system, email system) which isolates both the storage resource and the data from other applications. This approach means your organization has to scale these storage systems independently from other storage resources - and as the number of applications increases, so does the number of storage systems in your datacenter.
For the applications your developers are writing today, this storage model has several drawbacks which, according to the industry analyst firm Gartner, includes:
- It doesn’t efficiently scale to support new workloads
- It's bogged down by operational overhead
- It's difficult to match storage to application requirements
- It's time-consuming to adjust to workload changes and migrations
- It's manually managed, or at best semi-automated
These drawbacks become increasingly important as the rapid growth of unstructured data that many, if not most, enterprises are experiencing today continues. Nearly every industry is storing and serving more data at higher fidelity to an increasing number applications and users.
A key contributor to this is the rapid growth of unstructured data that many, if not most, enterprises are experiencing today. Nearly every industry is storing and serving more data at higher fidelity. The number of applications - and users - your enterprise storage systems need to serve is also increasing. Mobile devices, whether it be BYOD for the enterprise workforce or mobile consumer apps, have raised exceptions on how data is accessed, putting more demands on managing and scaling storage. And while data - on average - is growing 50% annually for organizations, the capability to manage that data with traditional storage architectures has not kept up.
In addition to increasing amounts of data, there has also been a significant shift in how people want and expect to access their data. The rising adoption rate of smartphones, tablets and other mobile devices by consumers, combined with increasing acceptance of these devices in enterprise workplaces, has resulted in an expectation for on-demand access to data from anywhere on any device.
This creates challenges for managing and scaling storage. One significant challenge is addressing the “efficiency gap” faced by many organizations because data is growing at an average of 50% annually, but the capability to manage that data with traditional storage architectures isn't keeping pace. This challenge is one which has many organizations turning to object storage as a solution.
Massive Scaling with Eventual Consistency¶
Fundamental requirements for storing large amounts of data are that you need throughput, scale and availability to data - which is difficult if you have all your data in one place. In traditional storage, the assumption was that all your data resided in the same server, rack - or data center. With massive amounts of unstructured data, that model no longer works since to get throughput, scale and availability, you need to approach your storage architecture in a different way and replicate data over multiple locations.
The problem with data storage is that you can't have everything. You have to choose between availability of data, consistency of data and the ability to withstand failures in storage hardware. As mentioned, today's users and applications want access to data -- when they want it and where they want it.
Storage systems generally use one of two different architectural approaches to provide the scalability, performance and resiliency needed: eventual consistency or strong consistency.
| Eventually Consistent Storage Systems | Strongly Consistent Storage Systems |
|---|---|
| Amazon S3 | Block storage |
| OpenStack Swift | Filesystems |
Block storage systems and filesystems are strongly consistent, which is required for databases and other real-time data, but limits their scalability and may reduce availability to data when hardware failures occur.
Strong consistency is required when all reads needs to be guaranteed to return the most recent data. With this approach, all nodes in the storage system must be queried to ensure that all updates have been written to all nodes and the read is returning the most recent copy. While databases with transactions require strong consistency, backup files, log files, and unstructured data do not need that same consistency. Based on this architecture, storage systems with strong consistency are difficult to scale, especially when it comes to multi-site configurations. This means that as the data grows, becomes more distributed—such as over multiple regions—or when there is a hardware failure, the chance for data not being available in a strongly consistent storage system increases.
By contrast object storage systems, such as Amazon S3 and Swift, are eventually consistent which provides massive scalability and ensures high availability to data even during hardware failures. In using an eventual consistency design, Swift doesn't create an "efficiency gap" for an organization, instead it allows them to keep up with the need to store, manage and access large amounts of data — including highly-available, unstructured application data.
In Swift, objects are protected by storing multiple copies of data so that if one node fails, the data can be retrieved from another node. Even if multiple nodes fail, data will remain available to the user. This design makes it ideal when performance and scalability are critical, particularly for massive, highly distributed infrastructures with lots of unstructured data serving global sites.
Each of these architectural approaches has its own definition, appropriate use cases, and trade-offs — all all of which need to be understood to appropriately identify which architecture is most appropriate for your data.
Swift Characteristics¶
Here is a quick summary of Swift’s characteristics:
- Swift is an object storage system that is part of the OpenStack project
- Swift is open-source and freely available
- Swift currently powers the largest object storage clouds, including Rackspace Cloud Files, the HP Cloud, IBM Softlayer Cloud and countless private object storage clusters
- Swift can be used as a stand-alone storage system or as part of a cloud compute environment.
- Swift runs on standard Linux distributions and on standard x86 server hardware
- Swift—like Amazon S3—has an eventual consistency architecture, which make it ideal for building massive, highly distributed + infrastructures with lots of unstructured data serving global sites.
- All objects (data) stored in Swift have a URL
- Applications store and retrieve data in Swift via an industry-standard RESTful HTTP API
- Objects can have extensive metadata, which can be indexed and searched
- All objects are stored with multiple copies and are replicated in as-unique-as-possible availability zones and/or regions
- Swift is scaled by adding additional nodes, which allows for a cost-effective linear storage expansion
- When adding or replacing hardware, data does not have to be migrated to a new storage system, i.e. there are no fork-lift upgrades
- Failed nodes and drives can be swapped out while the cluster is running with no downtime. New nodes and drives can be added the same way.
Swift enables users to store, retrieve, and delete objects (with their associated metadata) in containers via a RESTful HTTP API. Swift can be accessed with HTTP requests directly to the API or by using one of the many Swift client libraries such as Java, Python, Ruby, or JavaScript. This makes it ideal as a primary storage system for data that needs to be stored and accessed via web based clients, devices and applications.
According to the industry analyst firm Gartner, Swift is the most widely used OpenStack project as it is commonly used with other cloud computing frameworks and as a stand-alone storage system. Swift’s open design also enables it to be integrated with enterprise authentication system and IT management tools. Swift’s increasing adoption is reflected by how many of the most popular backup and content management applications now support Swift’s HTTP API.
Swift Requests¶
A foundational premise of Swift is that requests are made via HTTP using a RESTful API. All requests sent to Swift are made up of at least three parts:
- HTTP verb (e.g., GET, PUT, DELETE)
- Authentication information
- Storage URL
- Optional: any data or metadata to be written
The HTTP verb provides the action of the request. I want to PUT this object into the cluster. I want to GET this account information out of the cluster, etc.
The authentication information allows the request to be fulfilled.
A storage URL in Swift for an object looks like this:
https://swift.example.com/v1/account/container/object
The storage URL has two basic parts: cluster location and storage location. This is because the storage URL has two purposes. It’s the cluster address where the request should be sent and it’s the location in the cluster where the requested action should take place.
Using the example above, we can break the storage URL into its two main parts:
- Cluster location:
swift.example.com/v1/ - Storage location (for an object):
/account/container/object
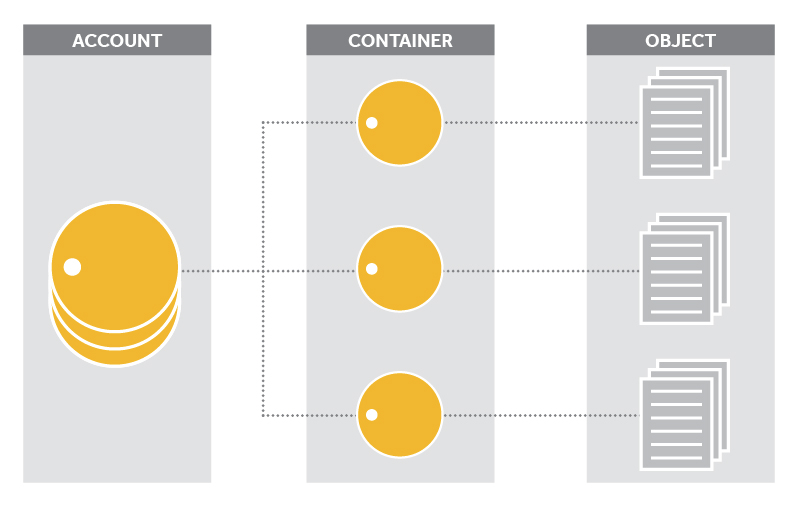
A storage location is given in one of three formats:
/account- The account storage location is a uniquely named storage area that contains the metadata (descriptive information) about the account itself as well as the list of containers in the account.
- Note that in Swift, an account is not a user identity. When you hear account, think storage area.
/account/container- The container storage location is the user-defined storage area within an account where metadata about the container itself and the list of objects in the container will be stored.
/account/container/object- The object storage location is where the data object and its metadata will be stored.
The Swift HTTP API¶
A command–line client interface, such as cURL, is all you need to perform simple operations on your Swift cluster, but many users require more sophisticated client applications. Behind the scenes, all Swift applications, including the command–line clients, use Swift's HTTP API to access the cluster.
Swift's HTTP API is RESTful, meaning that it exposes every container and object as a unique URL, and maps HTTP methods (like PUT, GET, POST, and DELETE) to the common data management operations (Create, Read, Update, and Destroy—collectively known as CRUD).
Swift makes use of most HTTP verbs including:
- GET—downloads objects, lists the contents of containers or accounts
- PUT—uploads objects, creates containers, overwrites metadata headers
- POST—creates containers if they don't exist, updates metadata (accounts or containers), overwrites metadata (objects)
- DELETE—deletes objects and containers that are empty
- HEAD—retrieves header information for the account, container or object.
Let's look at some sample HTTP GET requests to see how cURL would be used for
objects, containers, or accounts. Here we will use the storage URL
http://swift.example.com/v1/account. Common tasks a user might perform
with GET include:
- Downloading an object with a GET request to the object’s storage URL:
curl -X GET https://swift.example.com/v1/account/container/object- Listing objects a container with a GET request to the container’s storage URL:
curl -X GET https://swift.example.com/v1/account/container/- Listing of all containers in an account with a GET request to the account’s
- storage URL:
curl -X GET https://swift.example.com/v1/account/
While a CLI like cURL is all that is needed to perform simple operations on a Swift cluster, many people will want to use Swift client libraries to have applications make those underlying HTTP requests.
Client Libraries¶
Application developers can construct HTTP requests and parse HTTP responses using their programming language's HTTP client or they may choose to use open-source language bindings to abstract away the details of the HTTP interface.
Open–source client libraries are available for most modern programming languages, including:
- Python
- Ruby
- PHP
- C#/.NET
- Java
- JavaScript
Once a request is sent to the cluster, what happens to it?
Before we take a look at how the cluster handles a request, first let’s look at how a cluster is put together.
Swift Overview—Processes¶
A Swift cluster is the distributed storage system used for object storage. It is a collection of machines that are running Swift’s server processes and consistency services. Each machine running one or more Swift’s processes and services is called a node.
The four Swift server processes are proxy, account, container and object. When a node has only the proxy server process running it is called a proxy node. Nodes running one or more of the other server processes (account, container, or object) will often be called a storage node. Storage nodes contain the data that incoming requests wish to affect, e.g. A PUT request for an object would go to the appropriate nodes running the object server processes. Storage nodes will also have a number of other services running on them to maintain data consistency.
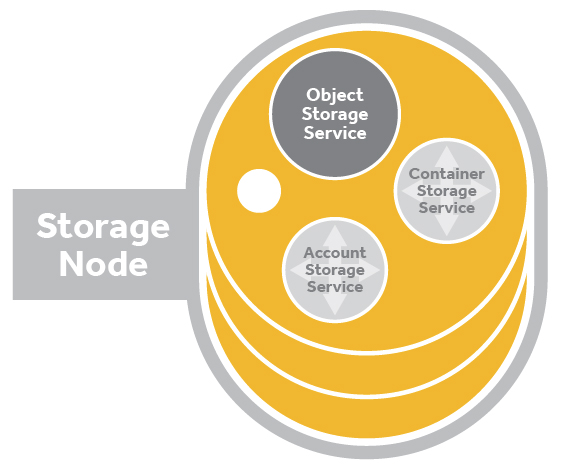
When talking about the same server processes running on the nodes in a cluster we call it the server process layer. e.g., proxy layer, account layer, container layer or object layer.
Let’s look a little more closely at the server process layers.
Server Process Layers¶
Proxy Layer¶
The Proxy server processes are the public face of Swift as they are the only ones that communicate with external clients. As a result they are the first and last to handle an API request. All requests to and responses from the proxy use standard HTTP verbs and response codes.
Proxy servers use a shared-nothing architecture and can be scaled as needed based on projected workloads. A minimum of two proxy servers should be deployed for redundancy. Should one proxy server fail, the others will take over.
For example, if a valid request is sent to Swift then the proxy server will verify the request, determine the correct storage nodes responsible for the data (based on a hash of the object name) and send the request to those servers concurrently. If one of the primary storage nodes is unavailable, the proxy will choose an appropriate hand-off node to send the request to. The nodes will return a response and the proxy will in turn return the first response (and data if it was requested) to the requester.
The proxy server process is looking up multiple locations because Swift provides data durability by writing multiple–typically three complete copies of the data and storing them in the system.
Account Layer¶
The account server process handles requests regarding metadata for the individual accounts or the list of the containers within each account. This information is stored by the account server process in SQLite databases on disk.
Container Layer¶
The container server process handles requests regarding container metadata or the list of objects within each container. It’s important to note that the list of objects doesn’t contain information about the location of the object, simply that it belong to a specific container. Like accounts, the container information is stored as SQLite databases.
Object Layer¶
The object server process is responsible for the actual storage of objects on the drives of its node. Objects are stored as binary files on the drive using a path that is made up in part of its associated partition (which we will discuss shortly) and the operation's timestamp. The timestamp is important as it allows the object server to store multiple versions of an object. The object’s metadata (standard and custom) is stored in the file’s extended attributes (xattrs) which means the data and metadata are stored together and copied as a single unit.
Consistency Services¶
A key aspect of Swift is that it acknowledges that failures happen and is built to work around them. When account, container or object server processes are running on node, it means that data is being stored there. That means consistency services will also be running on those nodes to ensure the integrity and availability of the data.
The two main consistency services are auditors and replicators. There are also a number of specialized services that run in support of individual server process, e.g., the account reaper that runs where account server processes are running.
Auditors¶
Auditors run in the background on every storage node in a Swift cluster and continually scan the disks to ensure that the data stored on disk has not suffered any bit-rot or file system corruption. There are account auditors, container auditors and object auditors which run to support their corresponding server process.
If an error is found, the auditor moves the corrupted object to a quarantine area.
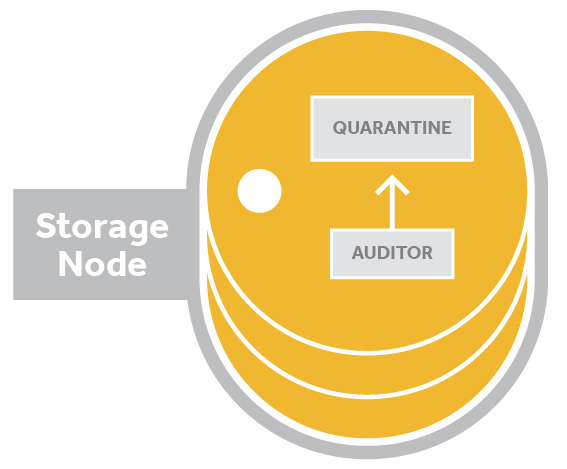
Auditors examine data and move to a quarantine area if any errors are found.
Replicators¶
Account, container, and object replicator processes run in the background on all nodes that are running the corresponding services. A replicator will continuously examine its local node and compare the accounts, containers, or objects against the copies on other nodes in the cluster. If one of other nodes has an old or missing copy, then the replicator will send a copy of its local data out to that node. Replicators only push their local data out to other nodes; they do not pull in remote copies in if their local data is missing or out of date.
The replicator also handles object and container deletions. Object deletion starts by creating a zero-byte tombstone file that is the latest version of the object. This version is then replicated to the other nodes and the object is removed from the entire system.
Container deletion can only happen with an empty container. It will be marked as deleted and the replicators push this version out.
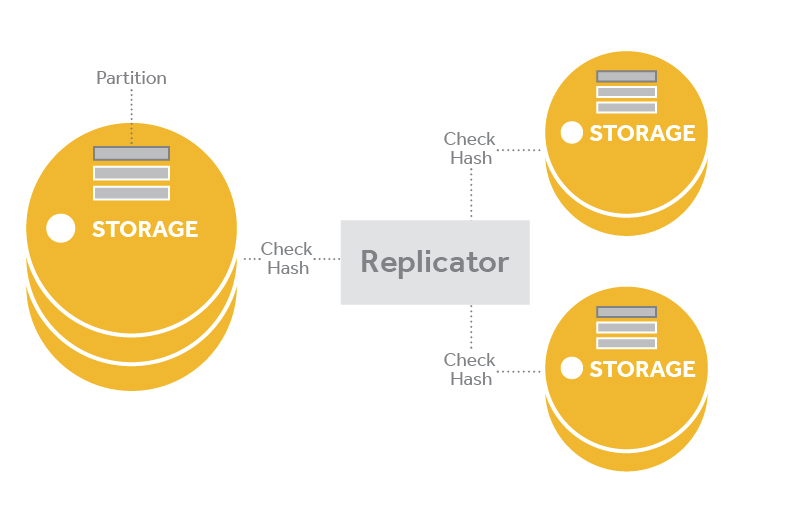
Replicators examine the checksums of partitions
Specialized Consistency Services¶
Container and Object Updaters¶
The container updater service runs to support accounts, it will update:
- container listings in the accounts
- account metadata
- object count
- container count
- bytes used
The object updater runs to support containers, but as a redundant service. The object server process is the primary updater. Only if it fails with an update attempt will the object updater take over and then update:
- object listing in the containers
- container metadata
- object count
- bytes used
Object Expirer¶
When an expiring object is written into the system, two things happen. First, the expiry time is saved in the object metadata. This prevents the object server from serving objects when their expiry has passed, even if the object still exists on disk. Second, a reference to the expiring object is stored in the cluster in a special "dot account".
The object expirer periodically checks the expiry "dot account" for references to objects that have expired. For any object references found, the expiry process will issue a DELETE request, and the data is removed from the cluster.
Account Reaper¶
When an account reaper service makes its rounds on a node and finds an account marked as deleted, it starts stripping out all objects and containers associated with the account. With each pass it will continue to dismantle the account until it is emptied and removed. The reaper has a delay value that can be configured so the reaper will wait before it starts deleting data—this is used to guard against erroneous deletions.
Swift Overview—Cluster Architecture¶
Nodes¶
A node is a machine that is running one or Swift processes. When there are multiple nodes running that provide all the processes needed for Swift to act as a distributed storage system they are considered to be a cluster.
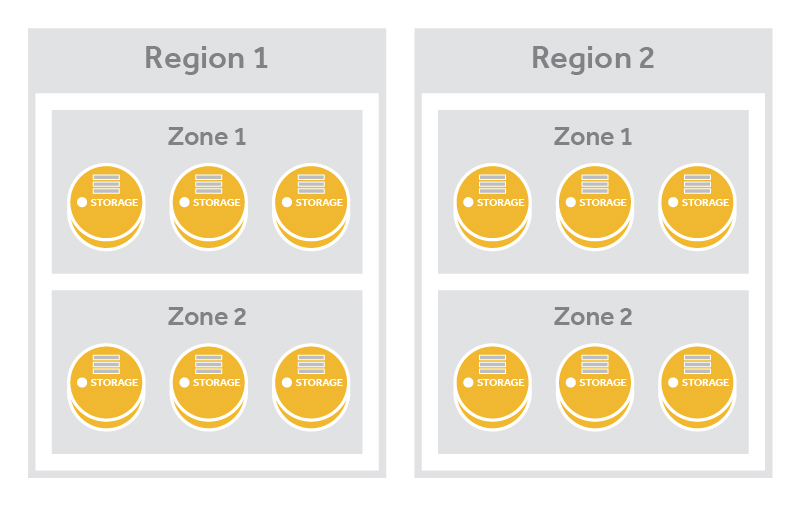
Within a cluster the nodes will also belong to two logical groups: regions and nodes. Regions and nodes are user-defined and identify unique characteristics about a collection of nodes-- usually geography location and points of failure, such as all the power running to one rack of nodes. These ensure Swift can place data across different parts of the cluster to reduce risk.
Regions¶
Regions are user-defined and usually indicate when parts of the cluster are physically separate --usually a geographical boundary. A cluster has a minimum of one region and there are many single region clusters as a result. A cluster that is using two or more regions is a multi-region cluster.
When a read request is made, the proxy layer favors nearby copies of the data as measured by latency. When a write request is made the proxy layer, by default, writes to all the locations simultaneously. There is an option called write affinity that when enabled allows the cluster to write all copies locally and then transfer them asynchronously to the other regions.
Storage zones can be deployed across geographic regions
Zones¶
Within regions, Swift allows allows availability zones to be configured to isolate failure boundaries. An availability zone should be defined by a distinct set of physical hardware whose failure would be isolated from other zones. In a large deployment, availability zones may be defined as unique facilities in a large data center campus. In a single datacenter deployment, the availability zones may be different racks. While there does need to be at least one zone in a cluster, it is far more common for a cluster to have many zones.

Storage can be placed in distinct fault-tolerant zones
Swift Overview—Data Placement¶
We have referenced several times that there are several locations for data because Swift makes copies and stores them across the cluster. This section cover the process in further detail.
When the server processes or the consistency services need to locate data it
will look at the storage location (/account, /account/container,
/account/container/object) and consult one of the three rings: account
ring, container ring or object ring.
Each Swift ring is a modified consistent hashing ring that is distributed to every node in the cluster. The boiled down version is that a modified consistent hashing ring contains a pair of lookup tables that the Swift processes and services use to determine data locations. One table has the information about the drives in the cluster and the other has the table used to look up where any piece of account, container or object data should be placed. That second table—where to place things—is the more complicated one to populate. Before we discuss the rings and how they are built any further we should cover partitions and replicas as they are critical concepts to understanding the rings.
Partitions¶
Swift wants to store data uniformly across the cluster and have it be available quickly for requests. Never ones to shy away from a good idea, the developers of Swift have tried various methods and designs before settling on the current variation of the modified consistent hashing ring.
Hashing is the key to the data locations. When a process, like a proxy server process, needs to find where data is stored for a request, it will call on the appropriate ring to get a value that it needs to correctly hash the storage location (the second part of the storage URL). The hash value of the storage location will map to a partition value.
This hash value will be one of hundreds or thousands of hash values that could be calculated when hashing storage locations. The full range of possible hash values is the “hashing ring” part of a modified consistent hashing ring.
The “consistent” part of a modified consistent hashing ring is where partitions come into play. The hashing ring is chopped up into a number of parts, each of which gets a small range of the hash values associated to it. These parts are the partitions that we talk about in Swift.
One of the modifications that makes Swift’s hash ring a modified consistent hashing ring is that the partitions are a set number and uniform in size. As a ring is built the partitions are assigned to drives in the cluster. This implementation is conceptually simple—a partition is just a directory sitting on a disk with a corresponding hash table of what it contains.
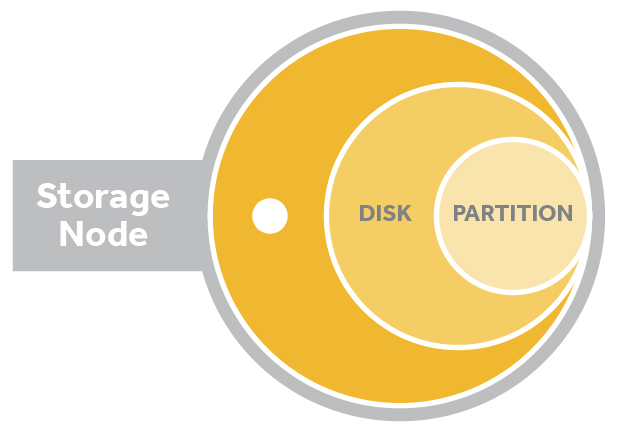
The relationship of a storage node, disk and a partition. Storage nodes have disks. Partitions are represented as directories on each disk
While the size and number of partitions does not change, the number of drives in the cluster does. The more drives in a cluster the fewer partitions per drive. For a simple example, if there were 150 partitions and 2 drives then each drive would have 75 partitions mapped to it. If a new drive is added then each of the 3 drives would have 50 partitions.
New storage will receive a proportion of the existing partition space
Partitions are the smallest unit that Swift likes to work with—data is added to partitions, consistency processes will check partitions, partitions are moved to new drives etc. By having many of the actions happen at the partition level Swift is able to keep processor and network traffic low. This also means that as the system scales up, behavior continues to be predictable as the number of partitions remains fixed.
Durability¶
Swift’s durability and resilience to failure depends in large part on the choice of replicas or erasure codes. The more replicas used, the more protection against losing data when there is a failure. This is especially true in clusters that have separate datacenters and geographic regions to spread the replicas across.
When we say replicas, we mean partitions that are replicated. Most commonly a replica count of three is chosen. During the initial creation of the Swift rings, every partition is replicated and each replica is placed as uniquely as possible across the cluster. Each subsequent rebuilding of the rings will calculate which, if any, of the replicated partitions need to be moved to a different drive. Part of partition replication including designating handoff drives. When a drive fails, the replication/auditing processes notice and push the missing data to handoff locations. The probability that all replicated partitions across the system will become corrupt (or otherwise fail) before the cluster notices and is able to push the data to handoff locations is very small, which is why we say that Swift is durable.
Previously we talked about a proxy server processes using a hash of the data’s storage location to determine where in the cluster that data was located. We can now be more precise and say that the proxy server process is locating the three replicated partitions each of which contains a copy of the data.
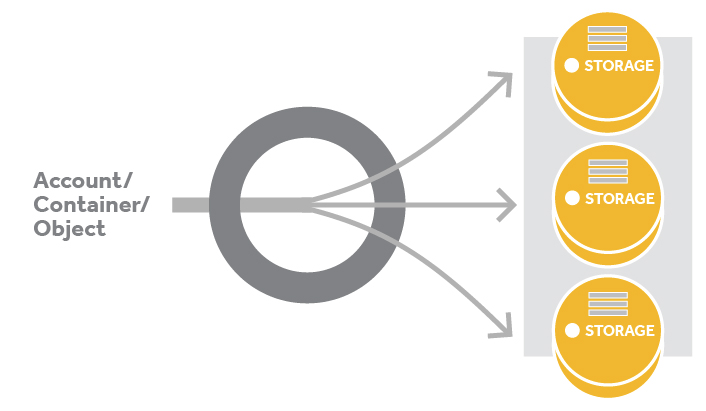
An object ring enables an ``/account/container/object`` path to be mapped to partitions
The Rings¶
With partitions and replicas defined, we can take a look the data structure of the rings. Each of the Swift rings is a modified consistent hashing ring. This ring data structure includes the partition shift value which processes and services use to determine the hash of a storage location. It also has two important internal data structures: the devices list and the devices lookup table
The devices list is populated with all the devices that have been added to a special ring building file. Each entry for a drive includes its ID number, zone, weight, IP, port, and device name.
The devices lookup table has one row per replica and one column per partition in the cluster. This generates a table that is typically three rows by thousands of columns. During the building of a ring, Swift calculates the best drive to place each partition replica on using the drive weights and the unique-as-possible placement algorithm. It then records that drive in the table.
Referring back to that proxy server process that was looking up data. The proxy server process calculated the hash value of the storage location which maps to a partition value. The proxy server process uses this partition value on the Devices lookup table. The process will check the first replica row at the partition column to determine the device ID where the first replica is located. The process will search the next two rows to get the other two locations. In our figure the partition value was 2 and the process found that the data was located on drives 1, 8 and 10.

The proxy server process can then make a second set of searches on the Devices list to get the information about all three drives, including ID numbers, zones, weights, IPs, ports, and device names. With this information the process can call on the correct drives. In our example figure, the process determined the ID number, zone, weight, IP, port, and device name for device 1.

Let's take a closer look at how partitions are calculated and how they are mapped to drives.
Building a Ring¶
When a ring is being built total number of partitions is calculated with a value called the partition power. Once set during the initial creation of a cluster, the partition power should not be changed. This means the total number of partitions will remain the same in the cluster. The formula used is 2 raised to the partition power. For example if a partition power of 13 is picked, then the total partitions in a cluster is 213 or 8192.
During the very first building of the rings, all partitions will need to be assigned to the available drives. When the rings are rebuilt, called rebalancing, only partitions that need to be moved to different drives, usually because drives were added or removed, will be affected.
The placement of the partitions is determined by a combination of replica count, replica lock, and data distribution mechanisms such as drive weight and unique-as-possible placement.
Replica Count¶
It should be remembered that it is not just partitions but also the replicated copies that must be placed on the drives. For a cluster with a partition power of 13 and a replica count of 3, there will be a total of 8192 partitions and 24576 (which is 3*8192) total replicated partitions that will be placed on the drives.
Replica Lock¶
While a partition is being moved, Swift will lock that partition's replicas so that they are not eligible to be moved for a period of time to ensure data availability. This is used both when the rings are being updated as well as operationally when data is moved. It is not used with the very first building of the rings. The exact length of time to lock a partition is set by the min_part_hours configuration option which often set to a default of 24 hours.
Weight¶
Swift uses a value called weight for each a drive in the cluster. This user-defined value, set when the drive is added, is the drive's relative weight compared to the other drives in the ring. The weight helps the cluster calculate how many partitions should be assigned to the drive. The higher the weight, the greater number of partitions Swift should assign to the drive.
Unique-as-possible Placement¶
To ensure the cluster is storing data evenly across its defined spaces (regions, zones, nodes, and disks), Swift assigns partitions using unique-as-possible placement algorithm. The algorithm identifies the least-used place in the cluster to place a partitions. First it looks for the least used region, if all the regions contain a partition then it looks for the least used zone, then server (IP:port), and finally the least-used disk and places the partition there. The least-used formula also attempts to place the partition replicas as far from each other as possible.
Once Swift calculates and records the placement of all partitions, the ring can be created. One account ring will be generated for a cluster and be used to determine where the account data is located. One container ring will be generated for a cluster and be used to determine where the container data is located. One object ring will be generated for a cluster and be used to determine where the object data is located.
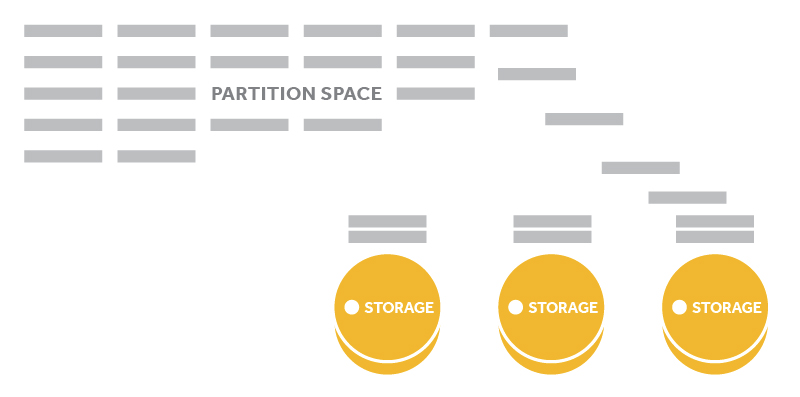
The partition space is distributed across all available storage.
There is a great deal to say about how Swift works internally and we encourage those who are interested in learning more to read the OpenStack Swift documentation.
Swift HTTP Requests: A Closer Look¶
Now that we have covered the basics of Swift, we can take all look at how to all works together. Let’s take a closer look at how a cluster handles an incoming request.
As mentioned earlier, all requests sent to Swift are made up of at least three parts:
- HTTP verb (e.g., GET, PUT, DELETE)
- Authentication information
- Storage URL (
swift.example.com/v1/account) - Cluster location:
swift.example.com/v1/ - Storage location (for an object):
/account/container/object - Optional: any data or metadata to be written
The request is sent to the cluster location which is a hook into the proxy layer. The proxy layer first handles the request verifying auth. Once the request passes auth the proxy layer will route the incoming request to the appropriate storage nodes.
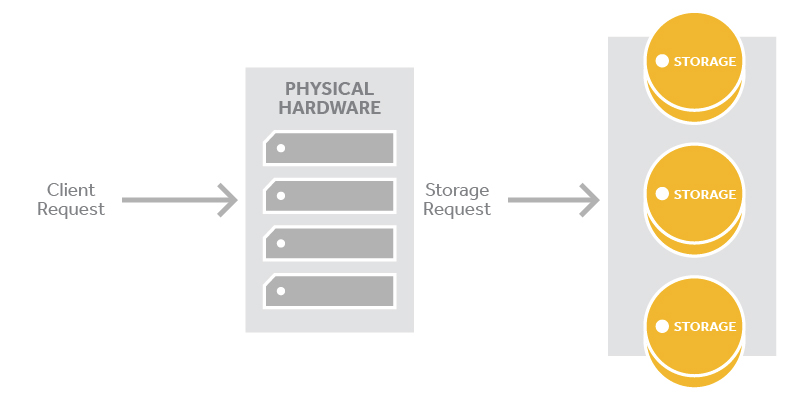
For our examples below, we will assume that the client has valid credentials and permission for the actions being taken and that the cluster uses three replicas.
Example: PUT¶
A client uses the Swift API to make an HTTP request to PUT an object into an existing container. Swift receives the request and one of the proxy server processes will handle it. First the proxy server process will verify auth and then it will take the hash of the storage location and look up all three partitions locations, the drives, of where the data should be stored using the object ring. The process then uses the object ring to look up the IP and other information for those three devices.
Having determined the location of all three partitions, the proxy server process sends the object to each storage node where it is placed in the appropriate partition. When a quorum is reached, in this case at least two of the three writes are returned as successful, then the proxy server process will notify the client is notified that the upload was successful.
Quorum writes ensure durability
Next, the container database is updated asynchronously to reflect the new object in it.
Example: GET¶
A client uses the Swift API to make an HTTP request to GET an object from the cluster. Swift receives the request and one of the proxy server processes will handle it. First the proxy server process will verify auth and then it will take the hash of the storage location and look up all three partitions locations, the drives, of where the data should be stored using the object ring. The process then uses the object ring to look up the IP and other information for those three devices. Having determined the location of all three partitions, the proxy server process will request the object from each storage node and return the object to the client.
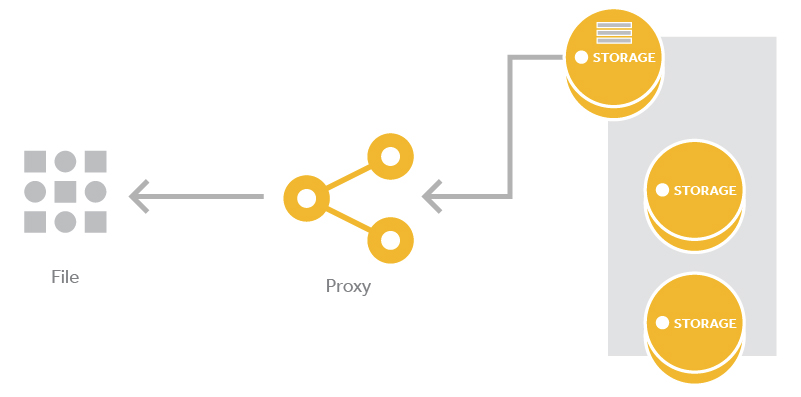
Get requests are handled by one of the storage nodes
Natively Built for the Web¶
Beyond the Swift’s core functionality to store and serve data durably at large scale, Swift has many built-in features that makes it easy for web application developers and end-users to use. Since Swift is written in Python, it is very flexible and can be extended with middleware that plug into the WSGI pipeline. By adding middleware in Swift’s proxy layer, it can be extended with additional features not possible in other storage systems and integrations with enterprise authentication systems, such as LDAP and Active Directory. Some of these features and integrations include:
- Static website hosting—Users can host static websites, including javascript and css, directly from Swift. Swift also supports custom error pages and auto-generate listings.
- Automatically expiring objects—Objects can be given an expiry time after which they are no longer available and will be deleted. This is very useful for preventing stale data from remaining available and to comply with data retention policies.
- Time-limited URLs—URLs can be generated that are valid for only a limited period of time. These URLs can prevent hotlinking or enable temporary write permissions without needing to hand out full credentials to an untrusted party.
- Quotas—Storage limits can be set on containers and accounts.
- Direct-from-HTML-form uploads—Users can generate web forms that upload data directly into Swift so that it doesn’t have to be proxied through another server
- Versioned writes—Users can write a new version of an object and keep all older versions of the object.
- Support for chunked Transfer-Encoding—Users can upload data to Swift without knowing ahead of time how large the object is.
- Multi-Range reads—Users can read one or more sections of an object with only one read request
- Access control lists—Users can configure access to their data to enable or prevent others ability to read or write the data
- Programmatic access to data locality—Deployers can integrate Swift with systems like Hadoop and take advantage of locality information to lower network requirements when processing data.