Planning and Managing Capacity¶
Data is always growing and drive capacity is always increasing. The question is how do you as an operator manage the capacity in a SwiftStack cluster?
How SwiftStack Distributes Data¶
By default, SwiftStack places data in cluster locations that are “as unique-as-possible”. With this data placement feature, Swift can intelligently place data on any storage device in the cluster, preferring locations that are in different zones, nodes and drives. All data stored in SwiftStack also has “handoff” locations defined, which are alternative data placement locations in the cluster should one of the replicas or erasure code fragments not be available due to a hardware failure.
SwiftStack levels data across all the devices and nodes in the system. A SwiftStack cluster uses a consistent hashing ring to randomly distribute all three replicas of an object across some of the drives through the drive in the cluster according to its size. What that means is it’s important for an operator to pay attention to the fullness of each and every drive and make sure that they’re not getting too full. A good rule of thumb is to keep at least 10-20% free, so that gives you some headroom to account for noticing and ordering new equipment, getting that hardware installed & configured.
Because a cluster stores data essentially level across every storage device in that policy, if the cluster is 80% full and you’re adding a new node or a new rack that’s 0% full, it has to come up to some percentage that will level the data across all the drives. If you do that all at once, there will be a lot of data moving in your network. Unfortunately that will have an impact on the performance of the existing activity to the cluster.
See SwiftStack Storage Policies for different ways to distribute data.
Adding Capacity¶
When you’re adding new capacity, you don’t usually add just one hard drive! If you’re adding new capacity maybe you’re adding at least a new server, or a rack. That's a pretty good chunk of data capacity. It's important to let the data flow into the new capacity you’ve added at a reasonable rate and not at the bottleneck rate of the network.
When adding new capacity, nodes or drives, to a SwiftStack cluster, data will be re-distributed evenly across cluster resources. For a large cluster, this may not be noticeable but for a small cluster, this additional replication traffic needs to be managed to ensure it does not impact performance of the cluster.
The SwiftStack Controller automates the process to adding capacity to the cluster. Additional drives can be added on existing nodes and new nodes can be added through the SwiftStack Controller.
The SwiftStack Controller will slowly increment the weights on each new device, rebalance and safely distribute the ring out to all the nodes. The SwiftStack Controller will also track information about replication activity so it knows when to do the next increment. On the node monitoring page, you can see the progress of each device as a percentage. On the Manage Node page, the drive's status will go from Ready to Adding to In Use.
Removing Capacity¶
Conversely, SwiftStack makes it easy to remove drives, which will be required when you want to upgrade to larger drives or swap out older drives. It looks just like capacity addition; just choose Remove, then wait until all data has been removed from the drive(s) so you can physically remove it from the cluster. See Node Drive Management for more information.
During the removal of a drive, the weight of the drive is gradually reduced by 36GB/hour, which forces data to be reallocated to other drives in the cluster. So, every hour there is a new ring pushed to the cluster, which triggers a rebalancing of the drives in the cluster. Removing data completely from a drive with 2TB of data on it will take approximately 56 hours, or close to 2.5 days [ 2,000GB / 36GB/hour = 56 hours ]. However, if the cluster is under heavy load or busy with other processes, it may drain less than 36GB of data per hour, which would make the removal process slower than calculated above.
Note
If, for any reason, a configuration push cannot be completed and the ring cannot be updated, the gradual removal of data will be interrupted. For example, if a node goes down and is not repaired and reinstated or removed from the cluster, the ring updating cannot continue until the cluster is healthy again. The gradual removal of data will continue once a new ring can be pushed to the cluster.
Full Drives¶
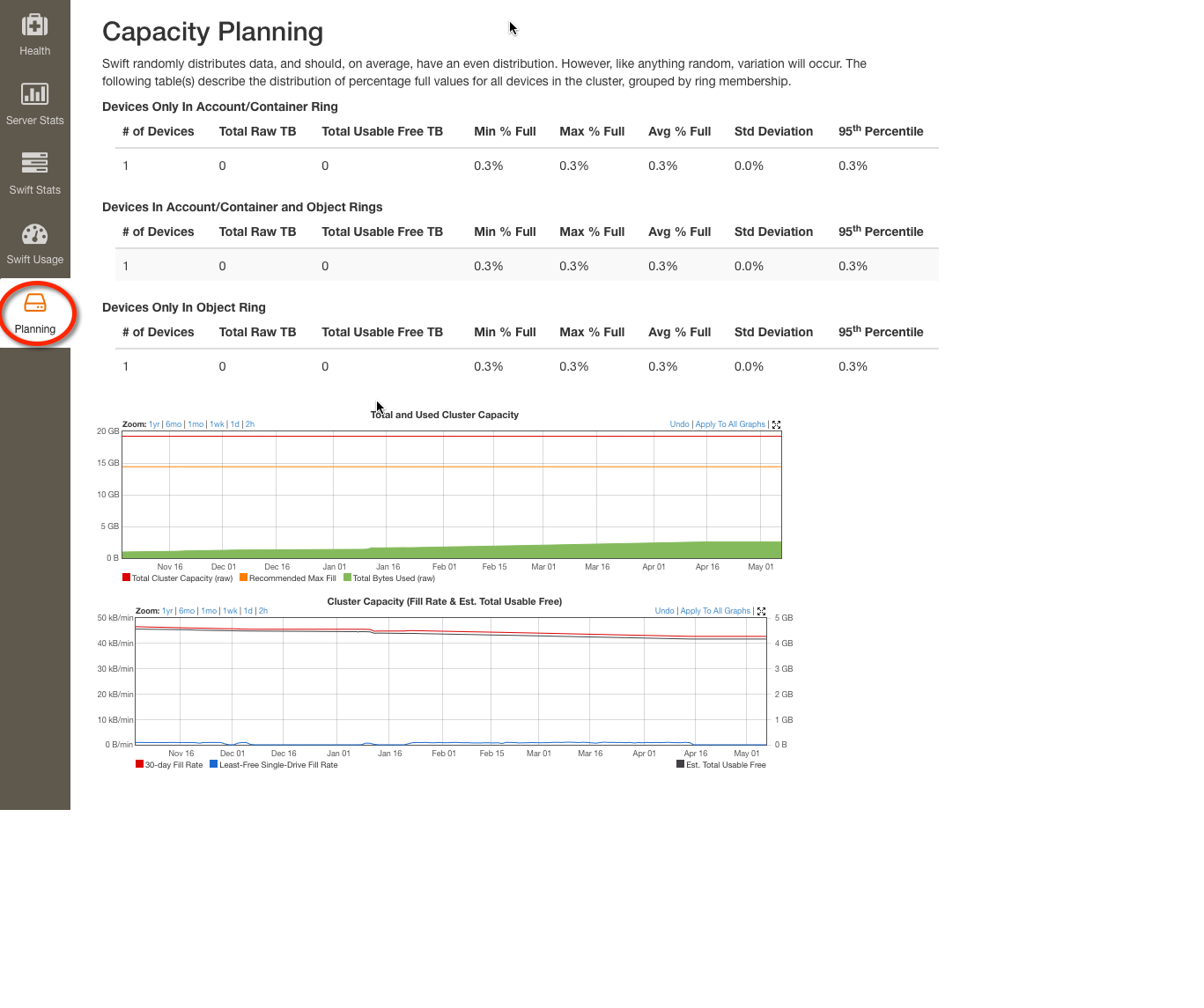
Another scenario to consider is how to handle full drives, which can happen if enough capacity has not been added to the cluster to keep up with data growth. As SwiftStack cluster distributes data across the cluster ‘evenly’, the most full drives will correspond to how full the overall cluster is and when you should consider adding additional capacity. Use the Capacity Planning tab to identify capacity shortages.